Token이란
- Manning & Schütze (1998)1 에서는 token을 Mark Twain의 Tom Sawyer를 통해 token을 설명함.
- 소설 전문에 있는 전체 단어가 71,370개 정도 존재하며, 이러한 ‘구분 가능한 단어의 출현’을 token이라고 지칭함.
- 따라서, 자연어처리 초기에는 word와 token간에 큰 차이가 없었으며, (word) token으로 오히려 token이 word를 지칭하는 형태로 인식됨.
- 이와 별개로, word의 출현 빈도에 따라 type을 정리하였으며 이를 token types라고 정의함.
…one can talk about tokens, individual occurrences of something, and types, the different things present.
- 또한 저자들은 영어가 시간에 따라 통계적인 특성이 변하는 고정된 통계적 특성을 가지는 것이 아니라고 언급하였으며, 이러한 특성이 있음에도 불구하고 확률적 추정에 기반한 언어 모델링이 가능하다고 설명함. 여기에서 시간이란, 단어가 위치에 따라 흐르는 것을 의미함.
…English in general is not a stationary ergodic process. But we can nevertheless model it with various stochastic approximations.
- 모델링: 언어의 확률적·계산적 형태로 표현함으로써, 그 언어를 분석·예측·생성할 수 있도록 하는 과정 또는 방법론을 의미하며, 따라서 모델링을 통해 언어를 기반으로 한 문제를 정의하고 이를 해석 또는 예측할 수 있음.
- 언어를 모델링할 때, 시간에 따라 다른 특성을 가지기 때문에 고정된 형태의 통계 정보를 활용하는 것이 아닌 단어 간에 상관관계 또는 출현 확률을 규칙화하면 특정 단어 뒤에 올 수 있는 단어를 예측할 수 있으며, 이를 조건부 확률 문제로 볼 수 있음.
- 언어 모델링에 사용하는 기본적인 개념인 Markov Chain과 n-gram은 추후에 다시 설명
Tokenizer란
- Tokenization: Manning & Schütze (1998)1 에서는 입력되는 input text를 단어나 숫자 또는 문장부호와 같이 작은 단위인 token으로 나누는 것을 tokenization이라고 설명함.
- Tokenizer: 이러한 일련의 tokenization process을 수행하는 도구이며, token의 기준에 따라 word나 character 단위로 text를 분리할 수 있음.
- 최근 LLM에서 사용되는 token의 개념은 WordPiece나 Byte Pair Encoding (BPE) 등 Transformer 기반 언어모델에서 주로 활용되는, word보다 더 작은 단위인 subword를 일컫음.
- Tokenizer의 궁극적인 목표는 언어 모델이 text 데이터를 처리할 수 있도록 token의 형태로 분리하여 이를 정수형의 식별자 (ID)로 변환하는 것이며, 이러한 식별자는 고정된 차원의 vector로 mapping되어 데이터 공간에서의 token 간의 상관관계를 수학적으로 계산할 수 있도록 함.
Tokenizer의 종류
WordPiece
- WordPiece (Schuster & Nakajima, 2012)2
- 일본어나 한국어와 같이 단어 간에 띄어쓰기가 거의 없거나 일부 존재하는 특성이 있으며, 특히 일본어의 경우 문자열마다 발음 방법이 너무 많아 적절한 분리 방법이 필요함.
- 또한, 웹문서의 경우 텍스트에서 글자들을 분리하기가 매우 어려워, 사전을 구축해도 사전에 존재하지 않는 out-of-vocabulary (OOV) 문제가 반드시 존재함.
- 이를 해결하기 위해, word를 character level로 분해한 후 이들을 기반으로 초기 token을 사전에 구축하며, 이후 특정 크기의 사전이 구축될 때 까지 corpus에서 token들이 등장할 확률 (likelihood)을 계산하여 가장 높은 점수를 가지는 연속된 token을 병합하여 subword를 구성하는 과정을 반복하여 최종 사전을 구축함.
(e.g. “happiness”가 “happi”+”ness”보다 사전에 존재할 확률이 높다면 “happiness” token 자체를 유지할 확률이 높음) - 실제 tokenization 시에 subword로 표현이 불가능한 경우 UNK 등 예약된 token으로 치환하여 최대한 OOV를 회피
- 특정 언어에 대한 도메인 지식 없이, text corpus에서 word 및 character 단위의 subword의 출현 빈도를 분석하여 통계적으로 tokenization을 가능하게 하나, 희귀 단어나 길이가 긴 단어에 대해서는 정보 손실 가능성이 존재함.
Byte Pair Encoding (BPE)
- Byte Pair Encoding (BPE)3 (Gage, 1994)
- BPE Tokenization4 (Sennrich et al., 2016)
- 데이터의 무손실 압축 방식으로 처음 소개되었으나, NLP Tokenizer에서도 subword 구성 시 효과적인 것으로 알려짐
- WordPiece처럼 초기 token 구성 시 character level로 분해하고 token을 합치는 것은 동일하나, WordPiece처럼 likelihood를 기반으로 병합할 subword를 결정하는 것이 아나라 corpus 내에서 가장 빈번하게 등장하는 연속된 subword pair를 우선적으로 병합하여, 특정 사전 크기를 만족할 때 까지 반복적으로 token 병합을 수행함.
Unigram LM
- Subword Regularization (Kudo, 2018)5
- ‘Unigram’이란 각 token (subword)가 서로 독립적임 (서로의 등장 여부에 영향을 미치지 않음)을 가정하며, 또한 모든 조합된 subword sequence의 출현 확률은 각 subword 의 출현확률의 곱으로 표현함.
…The unigram language model makes an assumption that each subword occurs independently, and consequently, the probability of a subword sequence X = (x1, … xM) is formulated as the product of the subword occurrence propabilities p(xi)…
- 사전 구축시에는 초기 subword 사전 후보로부터 여러 subword sequence 조합을 생성해, 그 중 출현 확률이 가장 높은 분할을 선택하여 반복적으로 사전 구축 수행
- 사전 크기를 줄일때에는 Viterbi 알고리즘을 활용
SentencePiece
- SentencePiece (Kudo & Richardson, 2018)6
- 기존 tokenizer/subword segmentation tool (WordPiece, BPE, Unigram)들이 정제된 입력을 요구하는 반면, SentencePiece는 input sentence를 그대로 활용하기 때문에 end-to-end하며 언어에 무관한 tokenization을 제공함.
…While existing subword segmentation tools assume that the input is pre-tokenized into word sequences, SentencePiece can train subword models directly from raw sentences…
- SentencePiece는 공개 당시 NLP에서 널리 활용되던 BPE4와 Unigram5 Tokenization을 모두 지원함
- 또한 pre-tokenization 과정을 생략하여 띄어쓰기가 거의 없는 중국어나 일본어에 대해서도 tokenization을 제공하며, 이 과정에서 space가 있는 언어에 대해서는 space 또한 subword에 포함하여 외부 리소스 (전처리/도구) 불필요.
Byte-Level Byte Pair Encoding (BBPE)
- GPT-27 (Radford et al., 2019)
- Byte-Level Subword Tokenization8 (Wang et al., 2020)
- GPT-2 연구에서 저자들은 일반화된 언어 모델은 어떠한 문자열에 대해서도 확률을 계산하고 생성할 수 있어야 한다고 설명하며, 현재의 LLM들은 소문자화, 토큰화, OOV 처리 등 전저리 과정을 필요로 하고 있음을 지적하였음.
- 유니코드 문자열을 UTF-8 byte로 처리하는 것이 앞서 언어모델이 요구하는 전처리 과정을 만족할 수 있지만, 현재 byte 수준에서의 언어모델은 연구 당시 성능이 word 수준 언어모델과 차이가 있음을 지적하였음.
- BPE Tokenization은 character와 word 사이에서 효과적으로 tokenization을 수행하고 있으나, 그 이름과는 달리 실제 hexadecimal이 아닌 유니코드 (실체화된 텍스트) 수준에서 subword handling이 이루어지고 있어, 유효한 문자열들만 포함하더라도 13만개 이상의 사전 크기가 필요하며, 이는 현재 BPE Tokenizer에서 사용하는 사전 크기의 32-64k보다 크다고 지적 (2024년 9월 10일에 발표된 Unicode 16.0 기준으로 154,998 char 존재)
- BPE를 unicode가 아닌 byte sequence에 바로 적용하는데에는 어려움이 있는데, 저자들은 문자열 외에도 함께 사용되는 특수문자가 있는 경우 BPE의 subword 병합 원리에 따라 이들이 함께 병합되며, 결과적으로는 같은 word임에도 불구하고 여러 형태의 variants가 사전에 존재하는 것을 관찰하여 사전의 slot과 언어모델의 학습공간을 낭비하는 결과를 초래한다고 지적함.
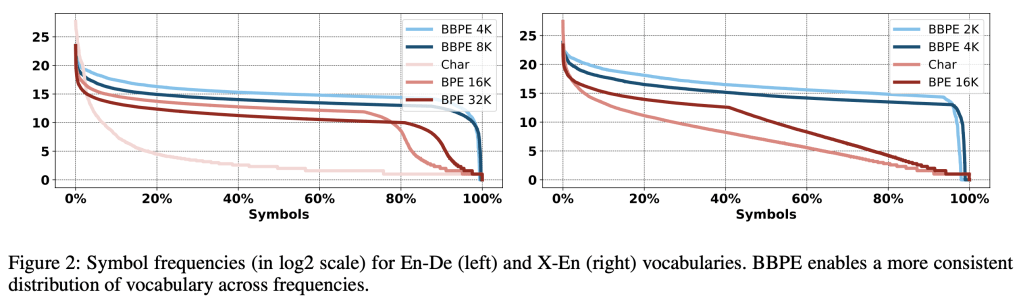
- 저자들에 따르면 byte-level에서는 최대 256개의 token을 표현할 수 있으나, 248개만으로 유니코드에 있는 대부분의 언어를 표현할 수 있다고 설명하였으며 BPE와 마찬가지로 자주 등장하는 subword byte를 병합하여 처리해야 하는 token 길이를 줄여 효율적인 연산이 가능하게 하였으며, 연구에서는 4K/8K/16K/32K의 크기로 실험하였으며 이때 BBPE 8K로도 BPE 32K보다 더 좋은 성능을 제시한다고 설명함.
…While there are 138K Unicode characters covering over 150 languages, we represent a sentence in any language as a sequence of UTF-8 bytes (248 out of 256 possible bytes).

References
- Manning, Christopher. Foundations of statistical natural language processing. The MIT Press, 1999. https://mitpress.mit.edu/9780262133609/
- Schuster, Mike, and Kaisuke Nakajima. “Japanese and korean voice search.” 2012 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2012. https://research.google/pubs/japanese-and-korean-voice-search/
- Gage, Philip. “A new algorithm for data compression.” The C Users Journal 12.2 (1994): 23-38. http://www.pennelynn.com/Documents/CUJ/HTML/94HTML/19940045.HTM
- Rico Sennrich, Barry Haddow, and Alexandra Birch. 2016. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1715–1725, Berlin, Germany. Association for Computational Linguistics. https://aclanthology.org/P16-1162/, https://arxiv.org/abs/1508.07909
- Taku Kudo. 2018. Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 66–75, Melbourne, Australia. Association for Computational Linguistics. https://aclanthology.org/P18-1007/, https://arxiv.org/abs/1804.10959
- Taku Kudo and John Richardson. 2018. SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 66–71, Brussels, Belgium. Association for Computational Linguistics. https://aclanthology.org/D18-2012/, https://arxiv.org/abs/1808.06226
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; and Sutskever, I. 2019. Language models are unsupervised multitask learners. https://openai.com/index/better-language-models/
- Wang, C., Cho, K., & Gu, J. (2020). Neural Machine Translation with Byte-Level Subwords. Proceedings of the AAAI Conference on Artificial Intelligence, 34(05), 9154-9160. https://doi.org/10.1609/aaai.v34i05.6451, https://ai.meta.com/research/publications/neural-machine-translation-with-byte-level-subwords/, https://arxiv.org/abs/1909.03341

Leave a comment